分布式数据系统
分布式数据系统的设计目的
- 扩展性,当数据量或者读写负载增长的时候,如何分散到多台机器上
- 容错与高可用性, 当单机出现故障,如何可以让系统继续工作。
- 延迟考虑,就近为用户选择数据中心来提供服务。
系统扩展的方式和考虑的问题
系统的扩展能力
水平扩展和垂直扩展。共享内存架构与共享磁盘架构。成本问题。资源竞争问题。
无共享结构
通过网络互联的节点,通过软件实现核心逻辑,提供统一的服务。
性价比高。
可以做到性能更强大。
复制与分区
将数据分布在各个节点上的方法。分区和复制。
数据复制
能够在多台机器上存储相同的数据副本。达到以下目的:
- 低延迟访问
- 高可用性
- 提高吞吐量
本章假设是数据规模比较小,一份数据拷贝可以完整的保存在一个机器中。分布式数据库成为主流也是最近发生的事情。
主节点和从节点,主从架构
一个节点负责写入,其他节点负责读。写入节点负责更新所有的从属节点。
工作流程:
- 指定一个副本为主,程序中对数据库所有的写操作都发送到这个主节点,主节点把数据写入自己的数据库中。
- 主节点写完自己的数据后,把对数据的更改作为log或者更改流发送给所有的从属副本。每个从属副本得到更新日志后,完成数据写入本地的操作。
- 客户端 读区数据时候,可以在任何节点上执行查询。但是只有主节点可以写。
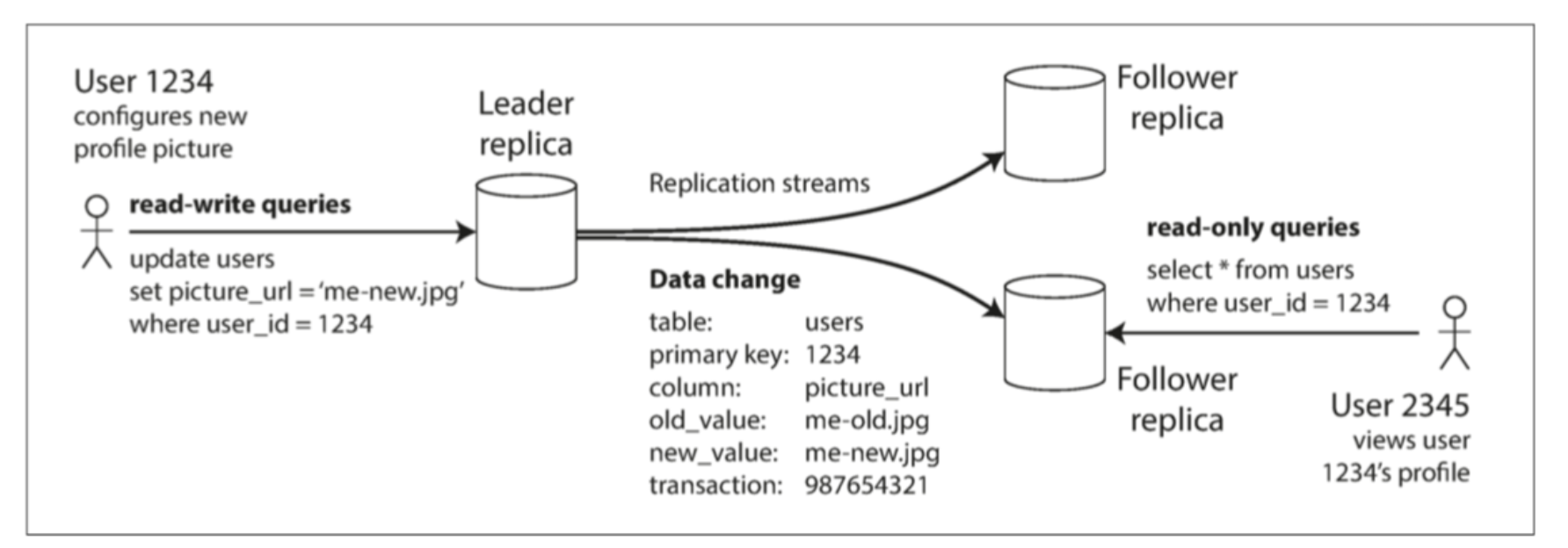
具有主从复制功能的数据库
关系型,PostgresSQL, MySQL, Oracle Data Guard, SQL Server。
非关系型,MongoDB, RethinkDB和Expresso。
分布式消息队列,Kafka,RabbitMQ
同步复制与异步复制
这是复制中非常重要的一个设计选项。对于关系型数据库,同步和异步是可以可配置的。而其他系统,只能hardcode一个选择。

- 节点1是同步,主节点需要等节点1写完之后才能向客户端确认
- 节点2是异步,主节点不需要等节点2给出完成写入的信息,就可以向客户端确认。
同步复制从节点的优点,从节点一直保留着最新的数据copy。如果主节点出现故障,从节点可以继续提供访问最新数据的能力。
缺点,如果同步节点无法确认,无论是网络原因还是其他原因,写入总会失败。主节点需要阻塞所有的写入操作直到从节点完成响应。
最佳配置是,一个同步节点,剩下的都是异步节点。这种配置也叫半同步。
达到极限吞吐量,就是全异步节点。但是无法保证持久化。有点是,无论从属节点怎么落后,都可以继续响应写入。
异步模式听起来不靠谱,但是还是被广泛使用,特别是那些从节点数量巨大或者分布地理环境特别广的情况。需要解决复制滞后问题。
增配新的从节点
如何加一个新的从节点?
简单的把数据文件拷贝是不够的,因为客户端有可能在复制的时候继续更新原来的数据。
锁定数据库,使其不可写,直到复制完成,会影响可用性。
解决方案操作步骤:
- 主节点在某个时间点生成快照文件。
- 把快照文件拷贝给新的从节点。
- 从节点连接到主节点,请求快照之后的更新日志。
- 从节点在快照文件的基础上执行这些更新日志,成为趋赶。接下来可以继续处理主节点的更新变化。并重复1到4.
处理节点失效
从节点失效:追赶式恢复
请求故障前最后一个事务滞后所有的更改,并且趋赶。
主节点失效:节点切换
需要把某个从节点升级成主节点。可以手动,可以自动。
自动切换步骤:
- 确认主节点失效。基于超时的机制:节点间互发心跳。
- 选举新的主节点。选离主节点版本最新的节点,来最小化丢失数据的风险。
- 重新配置系统,使主节点生效。客户端需要把写请求发送给新的主节点。等原来的主节点上线时,要把它降级为从。
主节点切换时会遇到的问题
- 异步复制的从节点,如果主节点挂掉之前,新的主节点并没有接收到最新的数据。这样当原来的主节点又上线后,需要处理写冲突的问题。通常的解决方案是原来主节点上没有完成复制数据丢弃掉。
- 丢弃数据的方案很危险。与主键分配有关,GitHub泄漏Private数据的例子。
- 两个节点都认为自己是主,称为脑裂。很危险,两个节点都接受写的请求,没有很好解决冲突的方法。可能需要强制关闭其中一个节点。
- 需要选择一个合适的超时时间来检测主节点失效。
复制日志的实现底层方式
基于语句的复制
执行SQL。有不适用的场景:
- 非确定性函数语句,NOW() RAND()等
- 自增列问题
- 有副作用的语句(触发器,SP,自定函数)
基于预写日志(WAL)传输
存储引擎的磁盘数据结构。每个写操作都是追加写的方式写入日志:
- 日志结构的存储引擎(SSTables,LSM-trees)。日志是存储方式
- Btree的覆盖写结构,每次都会写WAL日志。
不管哪种,都是日志。可以在另一个节点上构建copy。
缺点 日志描述的数据结构非常底层,与存储引擎紧密耦合。数据库升级如果存储格式改版,可能会有问题。
复制协议必须要求版本严格一致,升级就必须停机。
基于行的逻辑日志复制
与存储引擎采用不同的日志格式。
- 对于行插入,日志记录相关列的新值
- 对于行删除,日志表识这一行被删除
- 对于行更新,日志记录所有列的的新值
事务执行时影响到多行,会产生多个这样的日志记录,最后是一个commit日志。MySQL的binlog使用该方式。
这样的逻辑日志,容易向后兼容。
基于触发器的复制
优点高度灵活,
触发器执行自己写的应用代码,将数据的更改记录到一个单独的表中,然后外部逻辑处理这个表,完成自定义的逻辑,例如复制到另一个系统。
缺点开销更高
复制滞后问题
主从结构的复制,对于读操作密集的应用,如Web,是一个不错的选择。可以创建多个副本,来让读请求分配到就近的节点。
这种体系下的扩展,只需要添加更多的从副本,就可以提高服务器的吞吐量。但这种扩展一定是异步复制。这样会有复制滞后的问题。
这种不一致是一个暂时状态,但是并没有保证多长时间内会一致。也叫最终一致性(eventually consistency)。
读自己的写
用户自己的刚刚提交的数据,返回提交成功,但刷新页面后又看不到数据。可能是因为第二次读,是读到了一个没有最新数据的节点。
的一致性来防止这种异常.png)
我们需要写后读一致性
基于一些业务场景的方案:
- 用户修改自己的资料场景。读用户可能已经修改过的内容时,都从主库读。别人无法修改这份数据,只有一个客户端会修改时,需要客户端配合记录修改的操作。
- 如果这份数据可以被多个人修改,上面的方法就不行了。需要用其他的标准来决定是否去主库读。例如可以跟踪上次更新的时间,在上次更新后的一分钟内,从主库读。还可以监控从库的复制延迟,防止任向任何滞后超过一分钟到底从库发出查询。
- 客户端可以记住最近一次写入的时间戳,服务器检查这个时间戳和从库的同步时间比较。来验证数据是否有效。
- 如果副本分布在多个数据中心,则需要一个中心路由判断。
多客户端时会变得更复杂。需要跨设备的读写一致性。
其他问题:
- 记住用户上次更新时间戳的方法变得更加困难。元数据需要一个中心存储。
- 如很难保证来自不同设备的连接会路由到同一数据中心
单调读
读到新值后,之后不再会读到旧值。
看到新的评论刷新后又消失的例子。

确保每个用户总是固定的从一个副本中读数据。不要随记路由。
需要解决节点失效的影响。
前缀一致读
聊天记录的复制问题。对话,问答的happen before逻辑,需要在复制时候解决。不要乱序

这个是分区数据库的一个特殊问题,需要前缀一致读
一个解决方案时确保有因果关系的数据写入都交给一个分区解决。但是会影响效率。也有新的算法来解决逻辑先后问题。
复制滞后的解决方案
当需要对写后读等问题支持的时候,一定要小心同步复制和异步复制的配置问题,与系统设计时的思考一致,不然会出大问题。
应用层可以解决滞后问题,但是代价是更复杂更容易出错。
分布式事务,有人断言,最终一致性是分布式系统最终的选择。
多主节点复制
适用多数据中心的架构,如果是一般的单数据中心,还是主从好,因为简单不容易出错。
主从问题就是主节点网络中断后,写入操作都会出问题。
多主结构,就是有多个主节点接收写操作。数据中心之间的复制,由各自主节点之间通信,而数据中心内部的复制,由其中的主节点,复制到其他的从节点。
适用场景
多数据中心
多领导者配置中可以在每个数据中心都有主库。 图中展示了这个架构的样子。 在每个数据中心内使用常规的主从复制;在数据中心之间,每个数据中心的主库都会将其更改复制到其他数据中心的主库中。
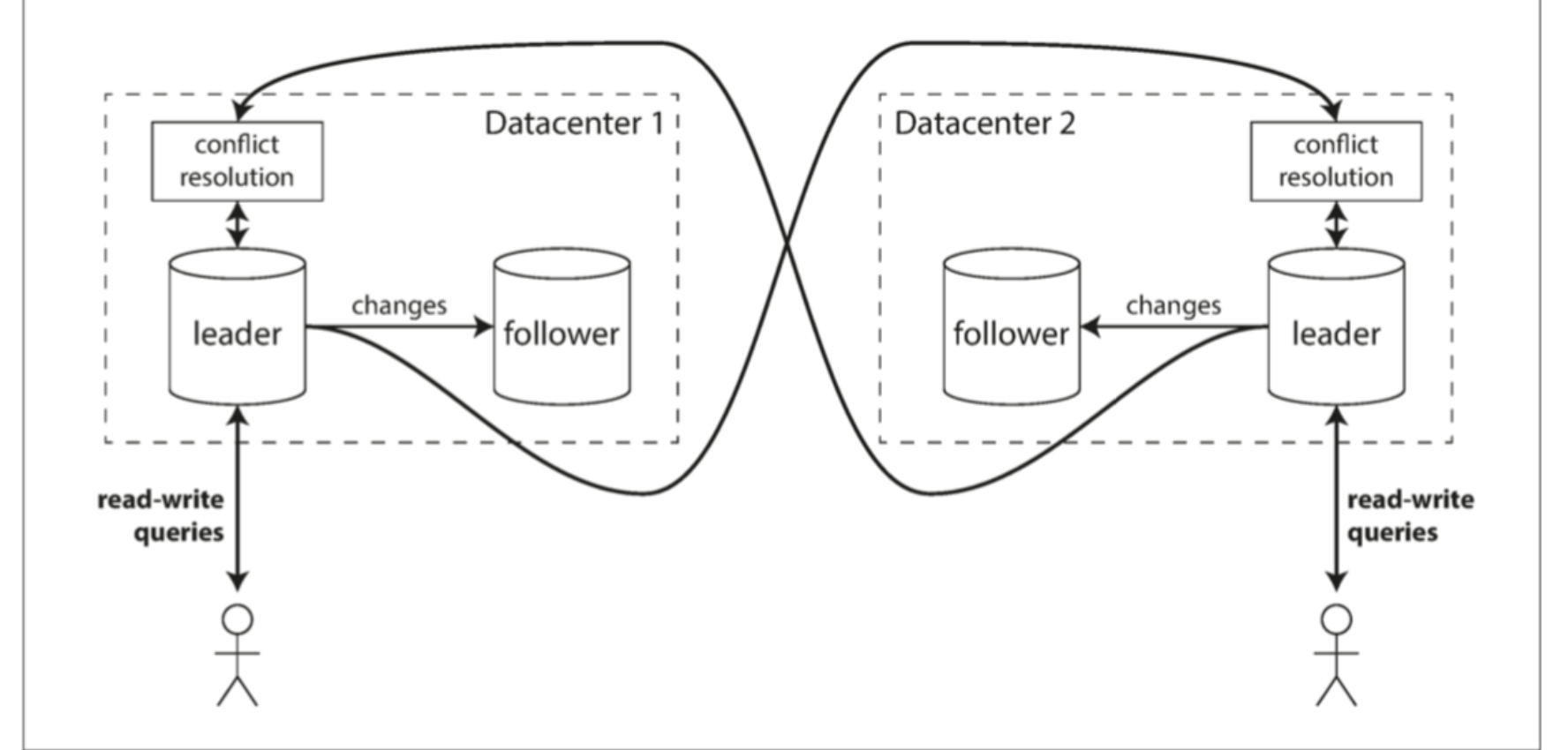
单主,多主复制之间的差异:
- 性能。
主从架构会影响写入延迟。多主结构,对于本地数据中心可以快速响应,然后用异步复制,复制到其他数据中心。 - 容忍数据中心失效
多主更好。没有切换操作。 - 容忍网络问题
多主更好。
商业数据库支持
多主复制MySQL的Tungsten Repliactor,PostgreSQL的BDR,Orcale的GoldenGate。
多主的缺点
必须处理写入冲突。
由于多主复制都是现在数据库中新增的高级功能,有些交互,触发器函数,自增主键等会有副作用。有些人认为多主很危险,应该尽量避免。
离线客户端操作
例如日历,Todo,会议安排等。每一个设备都是一个充当主节点的本地数据库。当设备再次上线时候,需要与服务器同步。
CouchDB就是为这种操作模式设计的。
协作编辑
Google Docs。
可编辑力度非常小,也会有多主复制的挑战—写入冲突。
处理写冲突(多主)
解决多主复制的最大问题。例子,多人编辑Wiki。
同步与异步冲突检测
简单的允许多主节点并行接受写请求,会产生冲突问题。
同步方式,需要所有主节点确认写入后才能返回,失去了多主节点的优势,退化成了单主结构。
避免冲突
- 总是把特定用户的更新请求路由到特定的数据中心。基本等价于主从模型
- 问题在于,如果某个数据中心故障,之前的配置需要被修改到可用的数据中心时,会有问题。无法避免冲突。
收敛于一致状态
- 给每个写入分配一个类似UUID的东西,选最高的ID为胜者。缺点,数据丢失。
- 为每个副本分配一个UUID,预先制定副本之间的优先级。缺点,数据丢失。
- 合并冲突数据。
- 保留冲突信息,给应用层解决。(时候解决冲突,可能需要提示用户)
自定义冲突解决逻辑
最适合的方式可能还是应用层程序来解决冲突。
在写入和读时执行冲突解决代码的逻辑:
- 写时执行
只要数据库系统在执行复制的change日志时,监测到冲突,就调用应用层的冲突解决程序。
Bucardo支持写Perl。这个解决方法通常只能后台运行。 - 读时执行
发现冲突时,把所有的冲突值都暂存起来。下一次读时,把这些值一并返回给应用层。让用户来处理。
CouchDB采用这样的处理方式。
冲突的定义
根据业务场景区分。有些显而易见,例如两个人同时修改一个record的某一列。有些不是这么直接,例如会议室预定系统,或者有限商品的秒杀系统。
自动冲突解决
冲突解决规则可能越来越复杂,而且自定义代码很容易出错。
一些方法:
- CRDT(conflict-free replicated datatypes),map orderedlist counter,可以用内置的方式自动解决。
- 使用可合并的数据结构。类似git的合并。
- 操作转换(operational transformation)是Google Docs等背后的解决方法。专门为可同时编辑的有序表设计。
拓扑结构
三种多主的复制拓扑结构
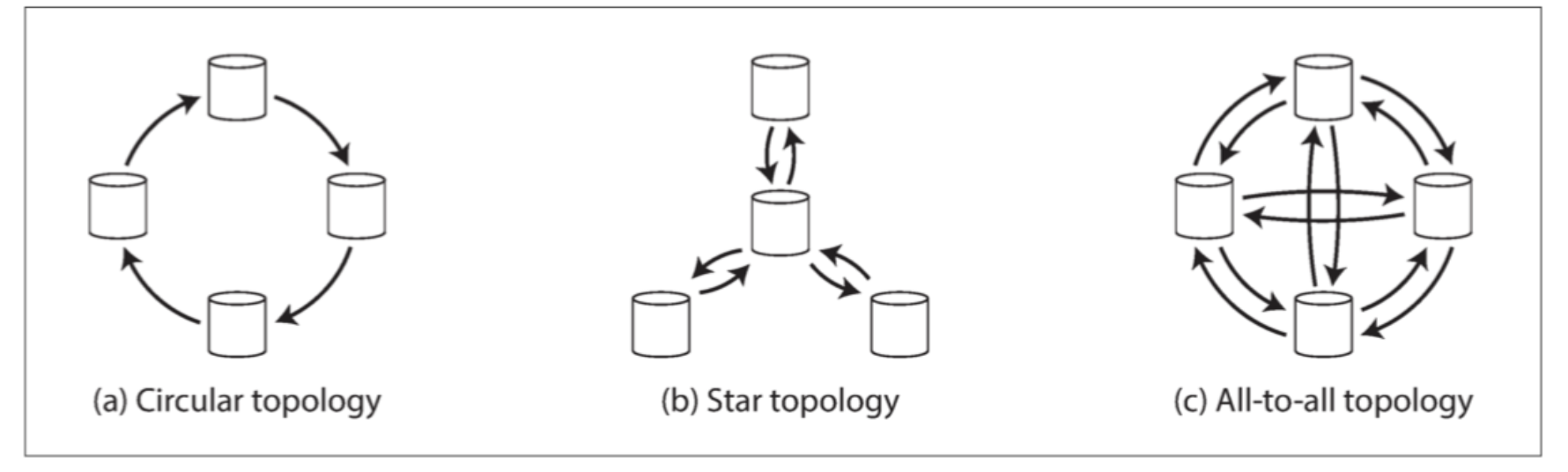
环形为防止无限循环,每个节点需要一个UUID,复制的时候带上已经完成过的节点ID。
星型和环形的问题,是节点故障。修复之前会影响其他节点。
全链路问题,某些链路快,某些慢,会导致复制日志覆盖,产生类似前缀一致读的问题。

无主节点复制
设计思路:放弃使用主节点,允许任何副本直接处理写请求。
这类数据库也被称为Dynamo风格数据库(不是AWS的那个,AWS的DynamoDB是单主架构)。
在一些无领导者的实现中,客户端直接将写入发送到到几个副本中,而另一些情况下,一个协调者(coordinator)节点代表客户端进行写入。但与主库数据库不同,协调者不执行特定的写入顺序。我们将会看到,这种设计上的差异对数据库的使用方式有着深远的影响。
节点失效时写入数据库
核心思想,并发读多个副本,使读到最新数据的概率达到最高。
读修复与反熵
- 读修复。并行读多个副本时,可以检测到过期的返回值。适合被频繁读取的场景。
- 反熵。后台进程不断查找副本之间的差异,完成更新。
并不是所有的系统都实现了这两个;例如,Voldemort目前没有反熵过程。请注意,如果没有反熵过程,某些副本中很少读取的值可能会丢失,从而降低了持久性,因为只有在应用程序读取值时才执行读修复。
读写quorum(法定人数)
w + r > n
写至少需要确认w个节点,读必须读到r个节点,n是副本总数。
通常w=r=(n+1)/ 2,也可以灵活配置。例如读多写少的情况,可以配置w=n,r=1.但是更容易写入失败。
仲裁条件定义了可以容忍的失效节点个数。
Quorum一致性的局限性
关键在于读写有重叠。即使在w+r》n的情况下,也存在返回旧值的边界条件。主要取决于现实情况:
- 如果采用了sloppy quorum
- 并发写冲突时候,需要根据时间戳挑选胜者,如果时钟偏差,会造成数据丢失。
- 读写同时发生,写操作可能只完成了一半节点,返回新旧值有不确定性。
- 如果写入失败,已经成功的节点不会回滚。会读到新值。
- 其他边界情况
无法得到复制滞后问题的一致性保证。
监控旧值
从运维的角度来看,监视你的数据库是否返回最新的结果是很重要的。
sloppy quorum与数据回传
- 容错能力。网络中断,无法满足法定人数,会使系统无法读,
- 无法满足法定人数时的出错处理。是否把错误返回客户端,或者是否还接收写请求。
- 放松仲裁方案允许不满足法定人数的写
- 一旦网络恢复,临时节点需要向原主节点完成数据传输(回传)。
在所有常见的Dynamo实现中,sloppy quorum是可选的。在Riak中,它们默认是启用的,而在Cassandra和Voldemort中它们默认是禁用的。
多数据中心操作
n是所有数据中心的节点总数。配置时,可以指定每个数据中心各有多少副本。
Cassandra和Voldemort在正常的无主模型中实现了他们的多数据中心支持。客户端通常只等待来自其本地数据中心内的法定节点的确认。
Riak将客户端和数据库节点之间的所有通信保持在一个数据中心本地,因此n描述了一个数据中心内的副本数量。数据库集群之间的跨数据中心复制在后台异步发生,其风格类似于多领导者复制
检测并发写
Dynamo风格的数据库允许多个客户端同时写入相同的Key,这意味着即使使用严格的法定人数也会发生冲突。
读修复或带数据回传时也可能会产生冲突。

解决冲突:
最后写入胜利(丢弃并发写入)
强制排序,例如时间戳,最大的获胜。是Cassandra唯一支持的冲突解决方法,也是Riak中的一个可选方案。
LWW(last write wins)缺点,牺牲数据永久性。
如果丢失数据不可接受,LWW是解决冲突的一个很烂的选择。
与LWW一起使用数据库的唯一安全方法是确保一个pk只写入一次,然后视为不可变,从而避免对同一个key进行并发更新。
Happens-before关系和并发
需要一个算法判断两个操作是否并发。比如插入之后才会更新。
确定先后关系
购物车的例子。
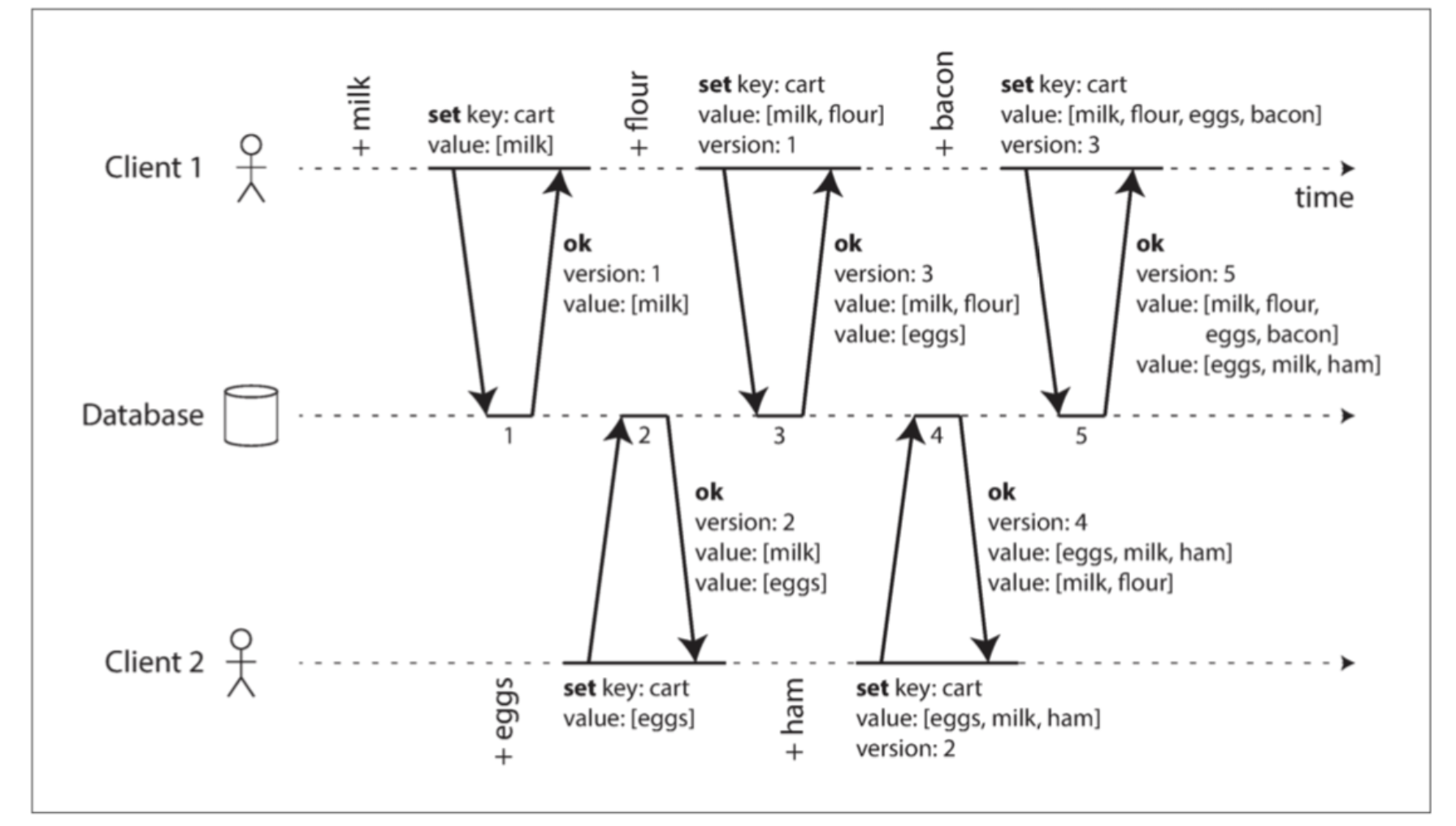
算法工作流程:
- 服务器维护pk的版本号
- 客户端读时,返回所有的值的最新版本号。(写前必须读)
- 客户端写pk时,必须传入之前读的版本号,读到的值和新值合并后的集合。
- 服务端接收到特定版本的写入时,覆盖版本号。
合并同时写入的的值
购物车例子中,加入商品操作,可以合并,去掉重复值。
删除适用墓碑标记。
使用专门的数据结构,CRDT。支持高校合并,删除标记。
版本矢量
多副本没有主节点的购物车。
需要为每个一个副本和每个主键都定一个版本号。每个副本在处理写入时增加自己的版本号,并且跟踪从其他副本中看到的版本号。这个信息指出了要覆盖哪些值,以及保留哪些值作为兄弟。
所有副本的版本号合集成为版本矢量。也有虚线版本适量。
另外,就像在单个副本的例子中,应用程序可能需要合并兄弟副本。