应用程序在根据需求不断的变化时,往往会对其存储的数据有更改的情况。
当数据格式或者模式发生变化的时候,经常需要对应用程序的代码修改。对于一个大型程序,这并非容易。
- 服务器应用需要滚动升级。这样部署新版本的时候,不需要停止服务。
- 客户端升级,只能寄希望于用户。很有可能用户永远不会升级。
升级中需要考虑的亮点:
- 向前兼容。新代码读老数据。(容易)
- 向后兼容。老代码读新数据。(难)
数据编码格式
程序中的数据,至少有两种不同的表示形式
- 内存中。
- 写入文件或者发送到网络中。
两种形式之间的转换,成为序列化Serialize和反序列化Deserialize。或者编码Encode,解码Decode。
语言特定的格式
比如Java中java.io.Serializable接口;Ruby的Marshal;Python的pickle等。
这类编码的问题:
- 编码和语言绑定在一起,无法跨语言使用。
- 安全问题。远程执行任意代码。可以恢复成任意类,意味着Decode的过程中需要有能力创建任意的类。
- 向前向后兼容问题。
- 效率低。比如Java内置序列化。
JSON,XML与它们的二进制遍体
XML被批评主要在于其冗长和不必要的复杂。JSON受欢迎主要是在Web浏览器中的原生支持。CSV格式简单,功能弱一些。
它们都是文本格式的,可读性强。但也有问题:
- 数字编码有很多模糊的地方。XML和CSV中无法区分数字和数字组成的字符串;JSON不区分整数和浮点数,而且不指定精度。
- 对Unicode字符串支持好,但是不支持二进制数据。所以人们使用Base64将二进制数据编码成String来传递。
- XML和JSON都有可选的模式支持。数据的正确性解释,取决于模式中的信息,
- CSV没有任何模式,需要程序解释。
二进制编码
更紧凑更快的解析格式。可以节省空间和时间。在TB级别的数据时尤其关键。
MessagePack
最最基础的二进制化JSON方式
1 | { |
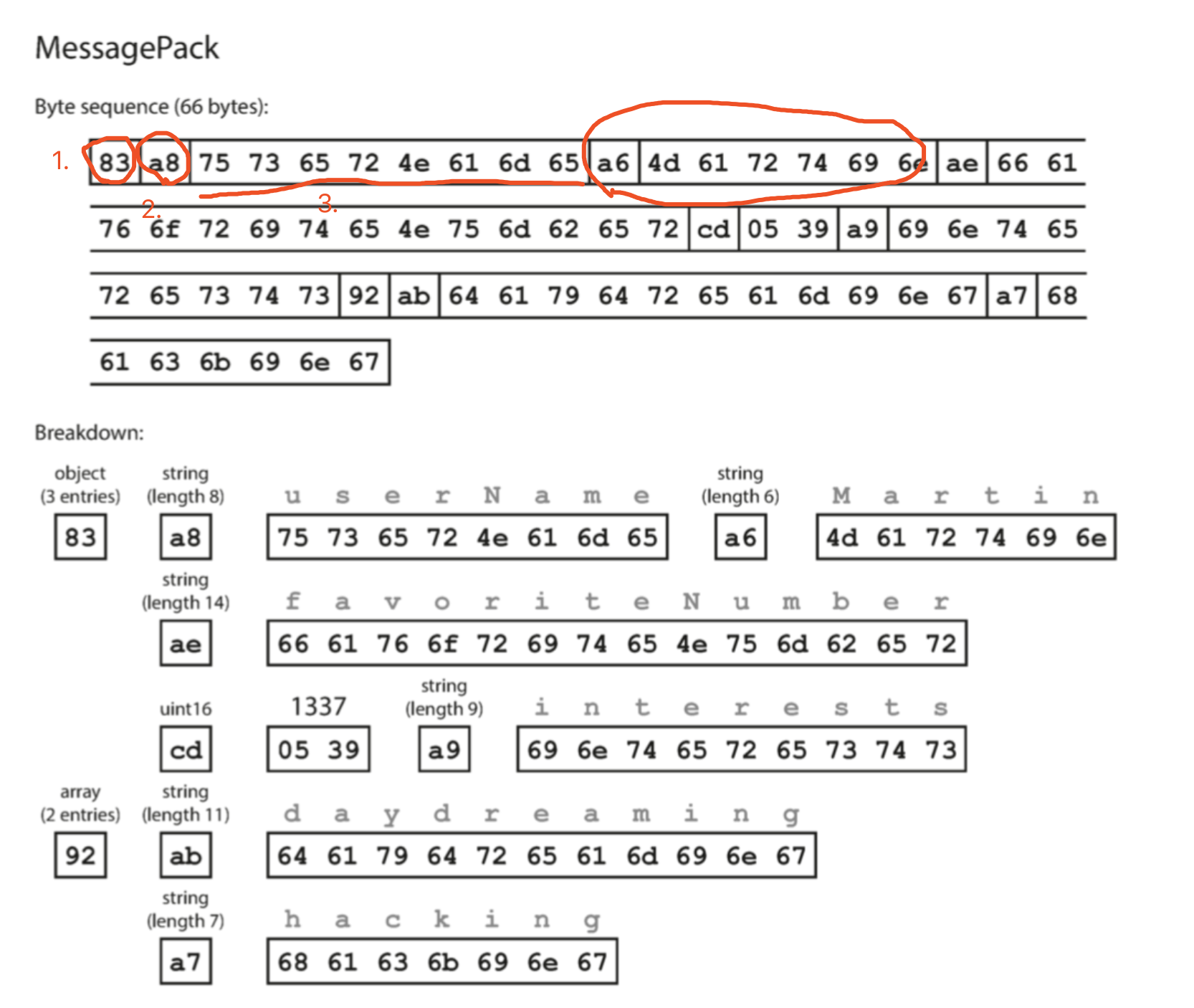
上图的二进制的结构解读:
- 第一个字节0x83,表示接下来是包含三个fields的对象(第四位0x03,高四位0x80)
- 第二字节0xa8,表示接下来的字符串,长度为八个字节
- 再往下的八个字节时ASCII的字段,userName
- 在接下来7个字节前缀0xa6表示后面有六个字节,Martin
结论:
整体编码占用66个字节,比原始的JSON编码(81个)少一些,但是不明显。
下面的方案中只用32个字节就可以完成同样记录的二进制化。
Thrift与Protocol Buffers
它们都是基于相同原理的二进制编码方式。都需要使用模式(Schema)来编码任意数据。
使用Thrift的接口定义语言(IDL)来描述模式:
1
2
3
4
5struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}使用Protocol Buffers的等效模式定义看起来非常相似:
1
2
3
4required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
Thrift和Protocol Buffers都有各自的代码生成工具,并支持各种编程语言。应用程序可以直接使用生成的代码完成Encode,Decode的工作。
Thrift的BinaryProtocal与CompactProtocol
BinaryProtocal
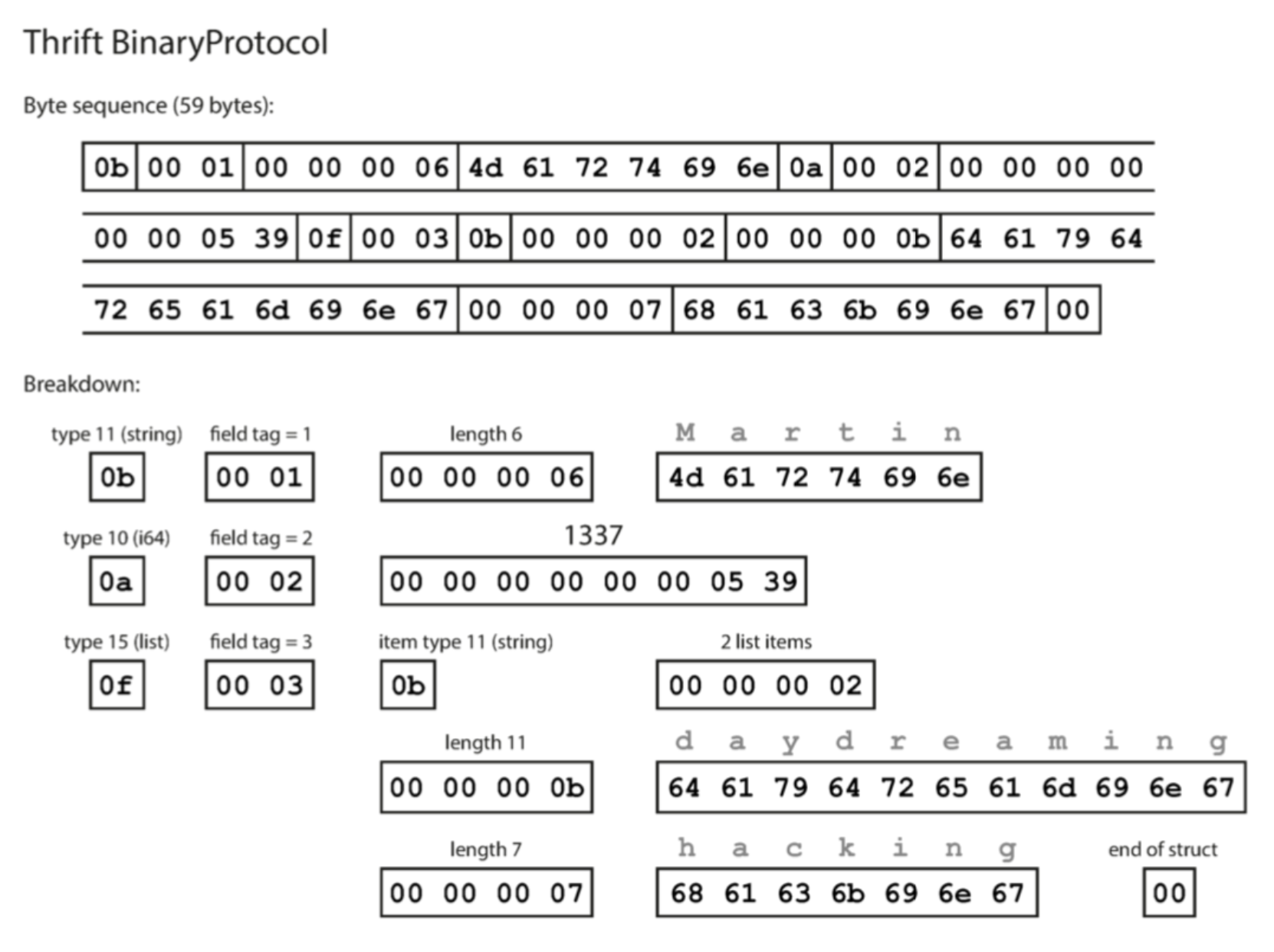
需要59个字节。
- 每个字段有一个类型注视(是字符串,整数,列表等),并可以指定长度(字符串长度,列表的count)
- 与MessagePack最大的区别是没有字段名。
CompactProtocol
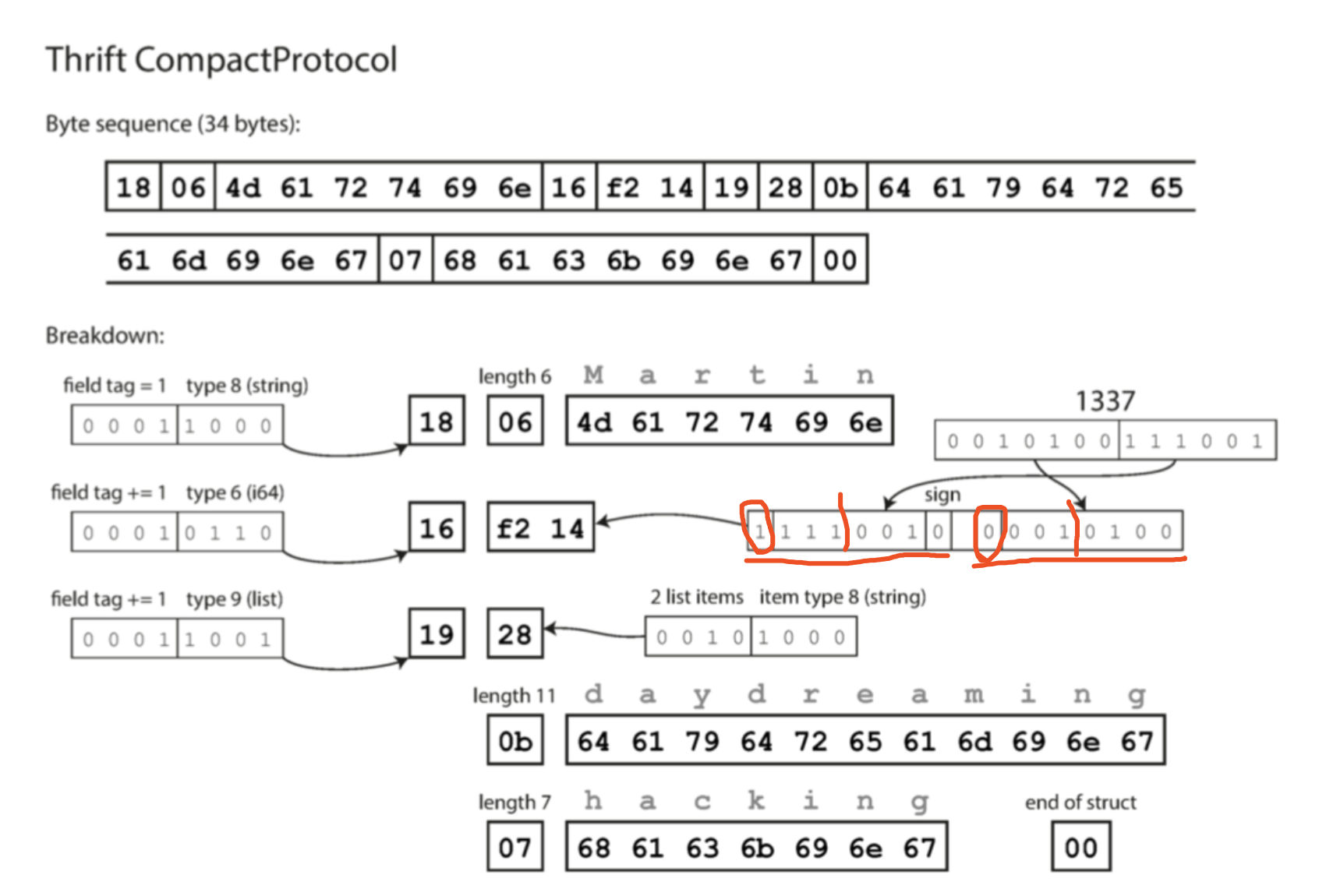
只需要34字节。
- 通过将字段类型和标签号打包在一个字节中。
- 使用可变长度整数。 1337,不用一个字节中的全部8位都表示数值。使用两个字节编码,每个字节的最高位表示是否还有更多字节。
- 可变长度整数意味着,-64到63的数字可以用一个字节表示,-8192到8191之间用两个字节。
Protocol Buffer编码
只有一种编码模式。与CompactProtocol很类似。只用33个字节。
不同之处:
- 表示字段位置和类型的一个压缩的字节中的位数分配不同
- 表示数字的填充方式不同。例如1337的表示一个是最左,一个是最右。
- 表示列表的方式不同,Thrift是有列表type,而protocol buffer是用重复的field tag来表示列表或者数组
- 没有end of struct
一个细节,optional字段对于编码encode的结果没有任何影响(二进制中不会体现一个field是optional的)。optional的体现在于在Runtime 时后可以做检查,捕获错误。
字段标签和模式演化
如何保证修改模型时候,既保证向前又保证向后兼容呢?
可以根据之前的例子看出,每个字段的标签号码(1,2,3等),与它的类型整合在一个字节中。由此看出field tag对编码数据的含义至关重要。
- 不能随便改字段的标签,会导致现有的编码无效。保证这个原则,实现向后兼容。
- 可以添加新的字段,只需要用一个新的标签。如果老代码读到带有新标签的数据,那么会忽略。这样可以向前兼容。
- 新增字段不可以是required字段,或者没有默认值的字段,向后兼容。违反的结果,会让老数据无法被新代码读。
- 删除字段只可以删除可选字段,老代码读新数据时才不会出检查问题,向前兼容。
数据类型和模式演化
改变数据类型会如何?可能是可以做的,但是风险在于丢失精度或者数据截断。
- 例如一个32位整数变成一个64位的整数。新代码可以读老数据,因为可以用0填充缺失的位。如果是老代码读64位的数据,使用32位int存,则会截断。
- Protocol Buffer中没有数组或者列表。所以如果把单值的类型变成列表类型的,老代码读新数据,只会留下最后一个值。而新代码没什么问题。
Avro
另一种二进制编码格式。由于Thrift不适合Hadoop的用例,因此Avro在2009年作为Hadoop的子项目启动。
Avro也用模式来制定数据结构的编码。它有两种语言:一种是Avro IDL,用于人工编辑,一种是基于JSON的易于机器读。
基于Avro IDL的模式的例子:
1 | record Person { |
其等价JSON格式如下:
1 | { |
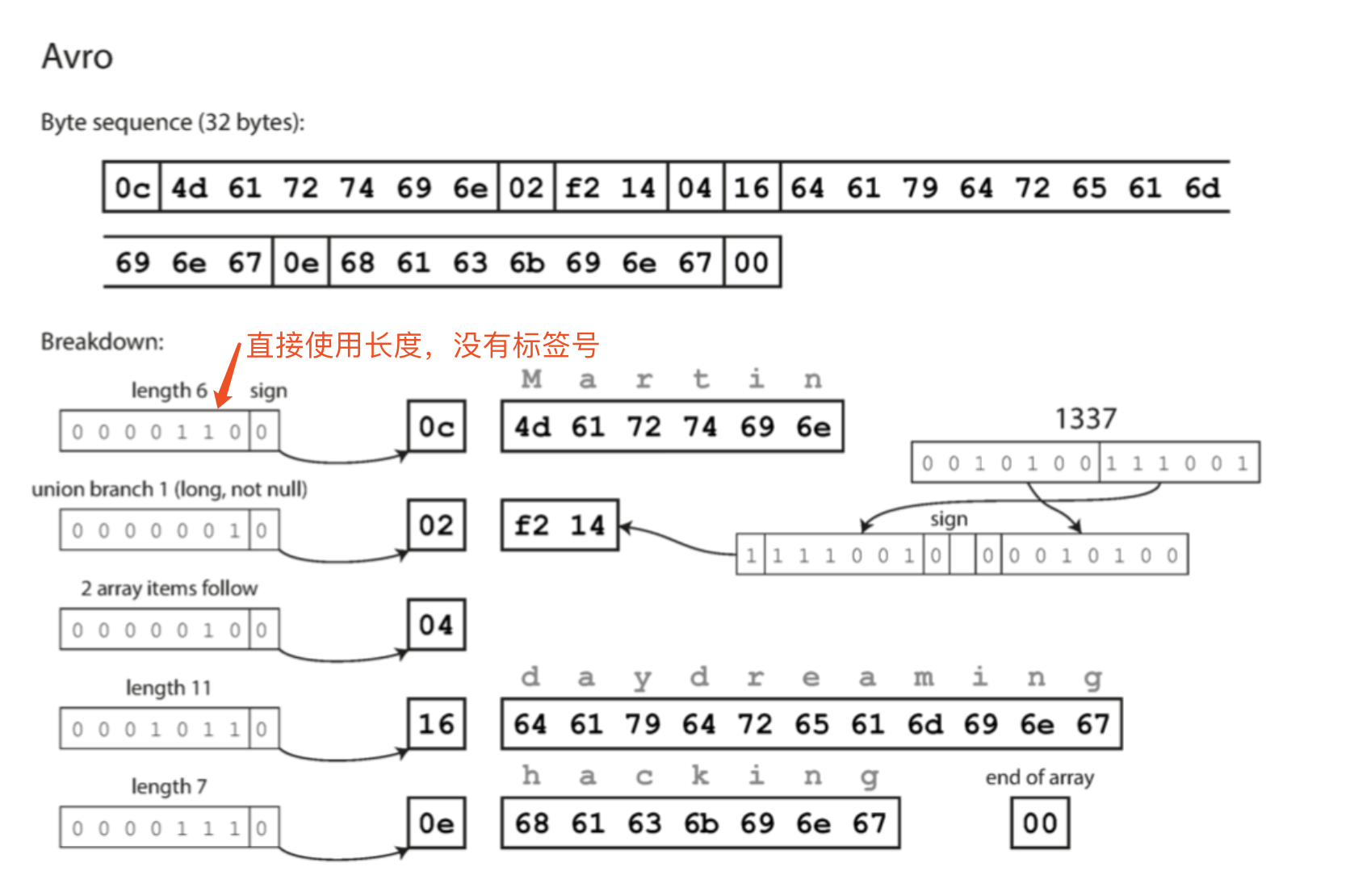
主要区别:
- 模式中没有标签号,是目前见过的所有编码中最紧凑的。
- 字节序列中也没有类型信息。只是连在一起的一些列值组成。字符串是长度加UTF-8的字节流,整数使用可变长度编码(与CompactProtocol相同)。但是并没有任何信息表示这些field是什么类型。
如何解析?
需要预先读区模式信息的数据,然后按照模式的顺序,遍历这些字段。
然后直接用模式中的字段信息来决定每个field到底是什么类型。
这意味着,读取数据的代码,必须使用当时写入数据是使用的模式,才可以正确还原数据。如果中间有任何不匹配,都无法解析。
Avro中的写模式和读模式
- 写模式。encode时,使用的模式,可以将这个模式编译在应用中。
- 读模式。decode时,应用代码依赖的模式,这个模式可能是在应用程序build过程中基于模式语言动态生成的。
Avro关键思想 ,写模式和读模式不一定需要完全一样,只需要兼容。当数据被Decode的时候,Avro的 Library通过对比查看写模式和读模式之间的差异,把数据从写模式转换成读模式,然后继续decode。Avro规范定义了这种解决方法的工作原理。
假如写模式和读模式的字段顺序不同,也没有关系,如果读的过程中遇到了只有在写模式中出现的字段,那可以忽略。如果在一个字段只在读模式中有,那么可以填充默认值。
Avro模式演化
- 只能添加或删除有默认值的字段。
- 如果添加一个没有默认值的字段,破坏了向后兼容性
- 如果删除一个没有默认值的字段,破坏了向前兼容性。
- null值的处理。
关键问题,写模式是什么?读模式如何直到某一个数据是用那个写模式编码的?
这个问题要取决于Avro使用的上下文:
- 有很多记录的大文件。
Avro常见场景。尤其是Hadoop的上下文中。上百万的数据,都是用相同的模式编码。这种情况下,该文件的写入模式可以嵌入到文件的开头。Avro可以制定一个文件格式来做到这一点。 - 具有单独写入记录的数据库
数据库中的记录,可能是在不同的时间点写入的。每个时间点可能使用不同的写入模式。最简单的发难是在每个编码记录的开始处,包含一个版本号,制定着写入模式的版本。在数据库的一个地方存储所有的写入模式列表。这样读取时可以直到数据的写入模式。Espresso就是这样工作的。 - 通过网络连接发送记录
连接双方可以在建立连接时,协商模式的版本,然后在这个连接会话中使用这个模式。这也是Avro RPC的协议原理。
动态生成的模式
Avro的一个重要优点就是不包含任何标签号。
不包含标签号是好理由: 动态生成模式更友好。
关系型数据库,使用二进制方式,把内容转存到一个文件的例子。
- 根据关系模型,生成Avro模式。并使用这个模式编码,把数据库内容倒入Avro对象容器文件中。列名对应Avro的field
- 如果数据库的关系模型发生变化,则可以更新Avro的模式,使用新的Avro导出数据。不需要关注模式的改变,字段是通过名字来表识的,所以更新后的写模式仍然可以和老的读模式匹配。
相比之下,Thrift和Protocol Buffer都需要手动分配新的标签。而且还需要完成从数据库列名到新标签的映射。
代码生成和动态类型语言
- 静态类型语言
Thrift和Protocol Buffer依赖于代码生成。定义了模式之后,可以跨语言使用模式。对于Java,C++等语言非常有用。可以转换成内存结构,并且支持IDE的类型检查。 - 动态语言(Javascript,Ruby,Python),因为没有编译时检查,代码生成没有什么意义。
- Avro为静态语言也提供了代码生成的工具,但是它也可以在在不生成代码的情况下使用。如果是一个嵌入了writer模式的对象容器文件,可以简单的使用Avro库打开,并用和JSON文件一样的方式查看。因为文件是字描述的。
模式的优点
- 模式语言简单。原理简单,使用更简单,广泛的编程语言支持。
- 比JSON,XML,CSV,更紧凑
- 模式有文档价值,不需要额外的手工维护的文档
数据流模式
数据库
向数据库中存储内容,就是在给未来的自己发送消息。
这种情况下,向后兼容是非常重要的。否则新代码无法读取存在数据库中以前写入的数据。
需要注意的一点是,老代码读区新代码写入的数据时,更新后又写会数据库,要当心不要丢失新数据格式的原来的信息。
将数据重写(迁移)到一个新的模式当然是可能的,但是在一个大数据集上执行是一个昂贵的事情,所以大多数数据库如果可能的话就避免它。
基于服务的数据流:REST与RPC
Web的方式,基于HTTP。
- 使用客户端(浏览器,移动应用,PC应用等)访问服务器数据。
- 使用服务器访问另一个服务器的Web服务。这样的应用构建方式最近叫做微服务。
微服务的关键设计目标是,通过使服务可独立部署和演化,让应用程序更易于更改和维护。这样每一个团队可以能够经常发布新的版本,而不必与其他团队协调。因此服务器和客户端之间的数据编码必须在不同版本的API之间兼容。
REST使一种HTTP服务的设计理念。SOAP基于XML,基于Web服务时,API被称为WSDL,支持代码生成。SOAP严重依赖工具,代码生成和IDE支持,与SOAP集成的成本很高。
RESTful的API更简单,格式如OpenAPI,Swagger。
由于互联网上存在广泛的安全威胁,REST的安全生态系统非常强大,从防火墙到OAUTH(身份验证/授权)
远程过程调用RPC的问题
看起来像是在使用本地方法。但是有缺陷需要解决:
- 网络请求不可预测。速度方面,网络失败,需要准备重试的逻辑。
- 可能超时,没有结果。无法知道发生了什么。
- 重试的时候,需要保证调用的方法有幂等性保证。
- 序列化时的问题,效率方面,编程语言方面的限制。
RPC发展
这种新一代的RPC框架更加明确的是,远程请求与本地函数调用不同。例如,Finagle和Rest.li 使用futures(promises)来封装可能失败的异步操作。Futures还可以简化需要并行发出多项服务的情况,并将其结果合并。 gRPC支持流,其中一个调用不仅包括一个请求和一个响应,还包括一系列的请求和响应。
使用二进制编码格式的自定义RPC协议可以实现比通用的JSON over REST更好的性能。但是,RESTful API还有其他一些显着的优点:对于实验和调试(只需使用Web浏览器或命令行工具curl,无需任何代码生成或软件安装即可向其请求),它是受支持的所有的主流编程语言和平台,还有大量可用的工具(服务器,缓存,负载平衡器,代理,防火墙,监控,调试工具,测试工具等)的生态系统。由于这些原因,REST似乎是公共API的主要风格。 RPC框架的主要重点在于同一组织拥有的服务之间的请求,通常在同一数据中心内。
RPC的数据编码和演化
假定所有的服务器都会先更新,其次是所有的客户端。只需要在请求上具有向后兼容性,并且对响应具有前向兼容性。
RPC方案中的向前向后兼容的解决方法,可他们在数据编码中使用的方法也有关。
异步消息传递,消息代理
中间件,可以低延迟的响应web请求。
优点:
- 如果接收方不可用,可以当作缓冲区,暂存消息,等恢复之后一起消费,实现HA。
- 可以自动重新发送消息到崩溃进程。防止丢消息。
- 结偶发送方和接收方,双方不需要知道对方的IP
- 支持广播,一条消息被多个人接收
- 子系统之间结偶
可以使用任何编码方式。只要兼容。
分布式Actor框架
并发编程模型。逻辑封装在Actor中。不直接操作线程。
由于每个Actor一次只能处理一条消息,因此不需要担心线程,每个Actor可以由框架独立调度。
分布式Actor框架中,编程模型被用来跨多节点进行scaling。位于不同节点之间的通讯可以使用encode decode的方式进行网络数据传输。
分布式Actor框架的实质是将消息代理(MQ等)和Actor编程模型集成到一个框架中。
三种流行的分布式Actor框架对于消息encoding的方式:
- 默认情况下,Akka使用Java的内置序列化,不提供前向或后向兼容性。 但是,你可以用类似Protocol buffer的东西替代它,从而获得滚动升级的能力。
- Orleans 默认使用不支持滚动升级部署的自定义数据编码格式; 要部署新版本的应用程序,您需要设置一个新的群集,将流量从旧群集迁移到新群集,然后关闭旧群集。 像Akka一样,可以使用自定义序列化插件。
- 在Erlang OTP中,对记录模式进行更改是非常困难的(尽管系统具有许多为高可用性设计的功能)。 滚动升级是可能的,但需要仔细计划。 一个新的实验性的maps数据类型(2014年在Erlang R17中引入的类似于JSON的结构)可能使得这个数据类型在未来更容易。